时间序列(Time Series)
时间序列(Time Series)指以时间为维度的一系列数值,常见的时间序列包括股市价格走势、天气预报中的温度走势等。下图展示了一个典型的时间序列:
时间序列预测
时间序列预测问题,即从当前时间点出发,去预测未来某个时间段内的数据值及波动情况。
时间序列预测方法包括传统的基于统计的方法、基于有监督机器学习的方法、基于深度学习的方法等。时间序列预测总结这篇文章中详细列举了各种方法的代表模型及相关案例。
本文主要将介绍两种用于时间序列预测的方法:
- LSTM (Long-Short Term Memory)
- xgboost
其中xgboost将时间序列预测问题转变为有监督学习问题。
LSTM
循环神经网络
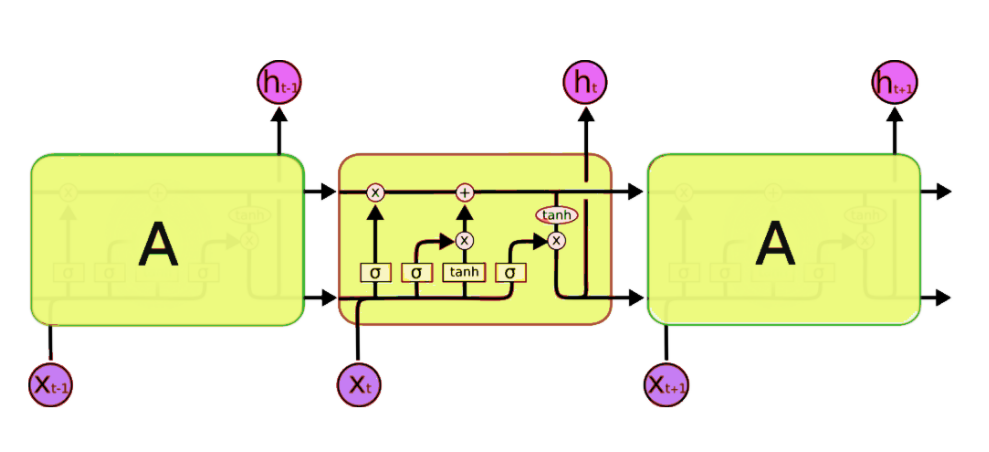
LSTM是循环神经网络RNN的经典变体,弥补了传统RNN对于长期记忆信息处理方式的缺点。一个vanilla LSTM网络结构如图:
另一个有名的RNN变体是GRU网络,它相比LSTM在cell结构上进行了改变,使得参数数量得到减少。
不过无论是传统RNN、LSTM还是GRU,循环神经网络在实际应用中的缺点是非常明显的。首先训练耗时长,这意味着模型很难进行在线训练,在保证响应速度的前提下只能通过离线训练。其次,难以并行化。RNN本身的step-by-step的梯度传导方式,如果计算资源有限,没有多台服务器和多个GPU时,则模型的训练很难实现并行。
XGBoost
如果你了解决策树、随机森林甚至GBDT,那么XGBoost的原理理解起来一定不会有太大问题。这是一个在校园里鲜为人知,却在工业界应用非常广泛的传统机器学习模型。它是由华人学者陈天奇提出的。
如果以后想从事算法相关的工作,请一定要在校园内提前学习xgb,到时你会为公司内xgb的应用之多而感到震惊。
项目实践
本篇主要介绍模型结构与特征构造,对于数据输入、预处理及训练预测的方式不做详细介绍。
模型结构
LSTM
在本项目中,采用keras进行LSTM模型搭建。相比tensorflow,选择keras的原因是它使用起来足够简单,能够进行快速实验及效果验证。模型结构定义代码如下:
import keras
from keras.layers.core import Dense, Dropout
from keras.layers import CuDNNLSTM
from keras.layers import Bidirectional, TimeDistributed
from keras.models import Sequential
class Model:
def __init__(self):
layers = [1, 50, 100, 1]
model = Sequential()
model.add(Bidirectional(CuDNNLSTM(layers[1],
return_sequences = True),
input_shape=(None, layers[0])))
model.add(Dropout(0.2))
model.add(Bidirectional(CuDNNLSTM(layers[2],
return_sequences = True)))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(layers[3],
activation = 'linear')))
self.model = model
def build_model(self):
return self.model
模型结构图:
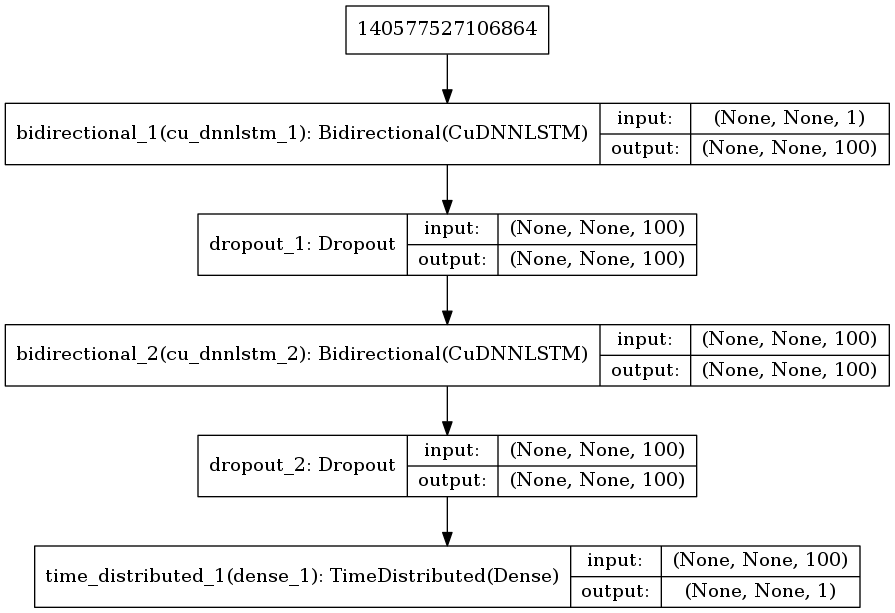
- CuDNNLSTM:与普通的LSTM区别在于,它只能在具有CuDNN和GPU的情况下使用。即使都使用GPU加速,CuDNNLSTM仍然比LSTM快很多,并且效果无明显差别。如果条件允许,优先选择CuDNNLSTM能帮你节省很多时间。
- Bidirectional:网络结构采用了双向LSTM(Bi-LSTM),并且两层Bi-LSTM进行stack,最后连接全连接层进行输出。
- TimeDistributed:使得LSTM从many-to-one变为many-to-many。即允许网络的output不是单一值,而是一系列的值。这样的LSTM近似可看做一个seq-to-seq网络。例如,many-to-one的场景下,当训练数据seq长度为48时(即48小时的数据),预测结果的长度为1(即预测未来1小时的数据量)。而在many-to-many的场景下,预测结果的长度也为48,即预测未来48小时的数据量。这里的例子中seq_length = future_steps,实际上也可以实现seq_length != future_steps。
XGBoost
XGBoost是临时起意做的实验,所以在重要的超参上没有花太多时间去调优。在这里主要介绍将时序预测转换为有监督学习时,如何构造数据的特征。
由于是回归任务,采用的模型为XGBRegressor:
import xgboost as xgb
model = xgb.XGBRegressor(
n_estimators=500,
n_jobs=-1,
subsample=0.75,
max_depth=5,
colsample_bylevel=0.8
)
当转换为有监督学习的回归任务时,输入数据的特征则从每一维度的时间上进行提取,例如日期、年份、小时等。回归任务的目标值则为我们需要预测的序列数值。
import pandas as pd
def create_features(self, df):
df['date'] = pd.to_datetime(df['date'])
df['hour'] = df['date'].dt.hour
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['dayofmonth'] = df['date'].dt.day
df['weekofyear'] = df['date'].dt.weekofyear
X = df[['hour', 'dayofweek', 'quarter', 'month', 'year', 'dayofyear', 'dayofmonth', 'weekofyear']]
y = df['value']
return X, y
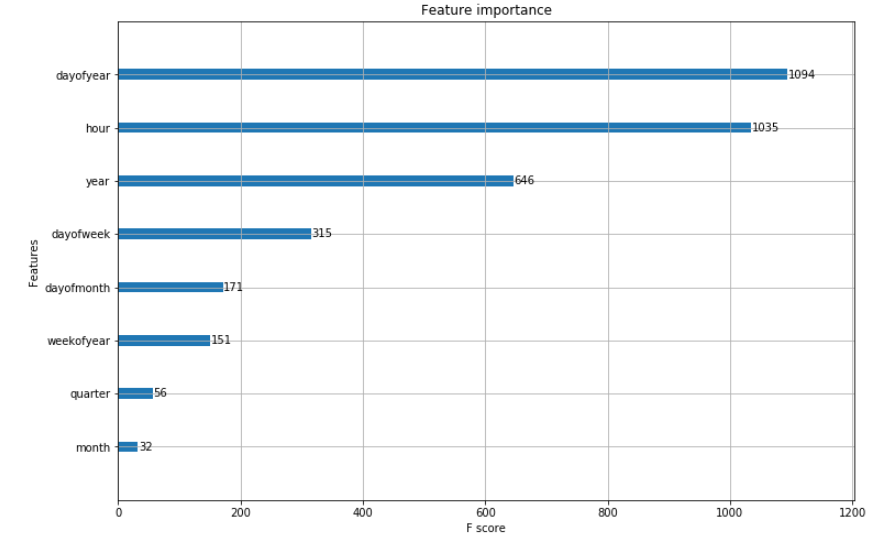
模型训练完成,输出特征重要性:
实验结果
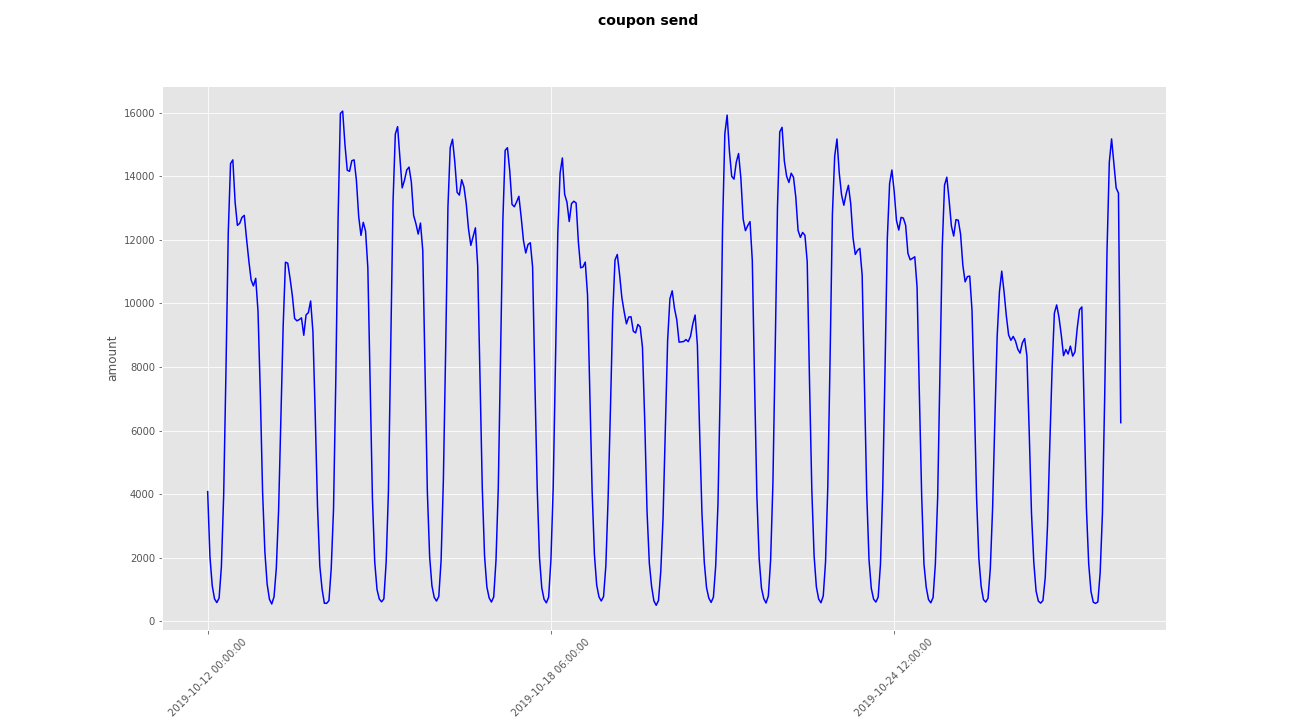
两个模型均在多个数据集上进行训练及验证,在这里以其中一个数据集为例进行展示。
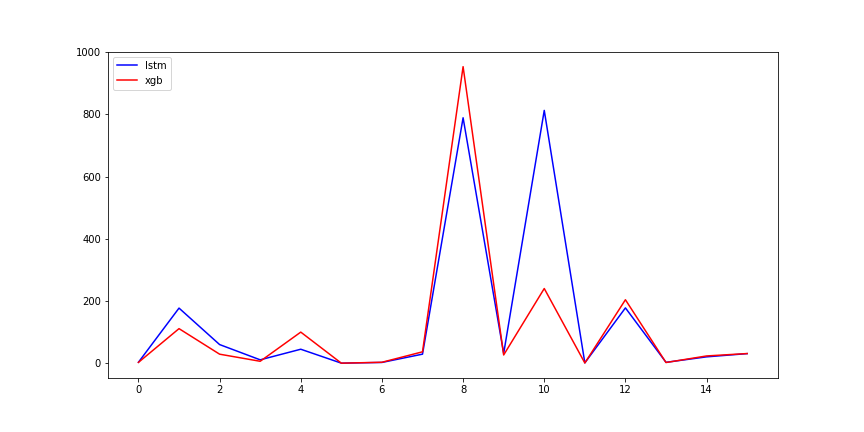
预测结果曲线
LSTM:
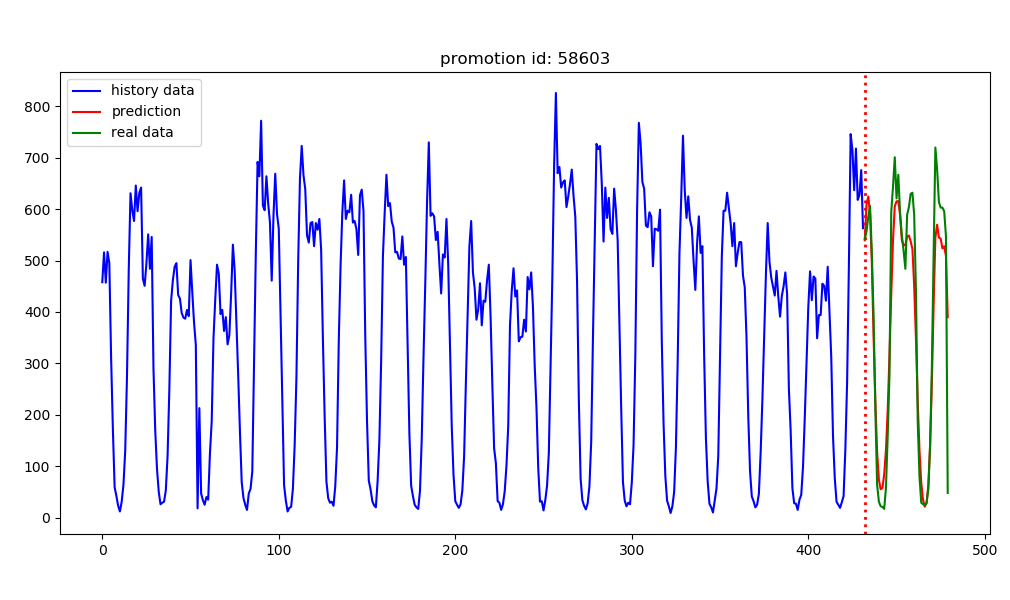
XGBoost:
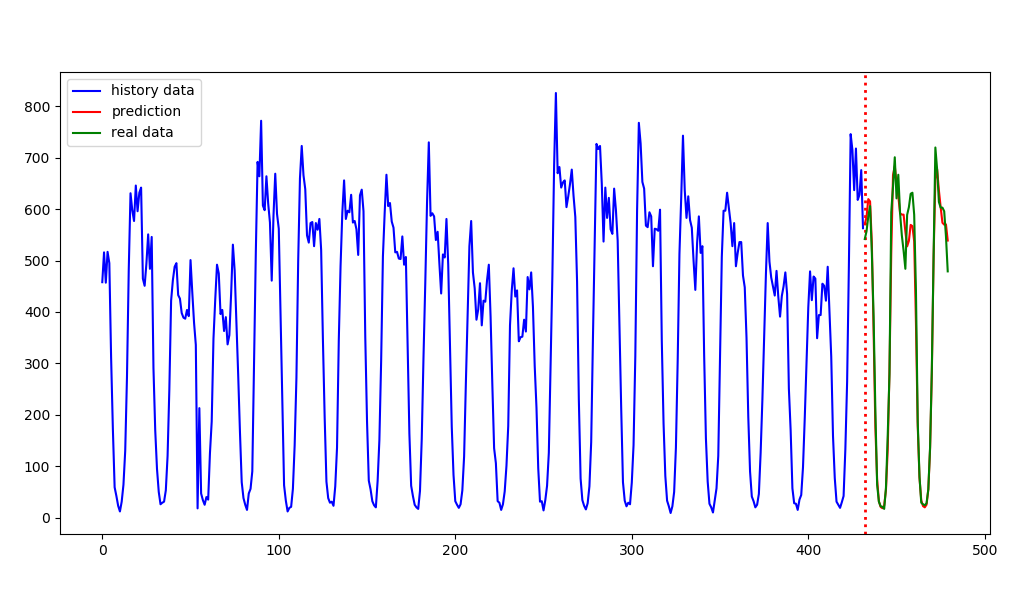
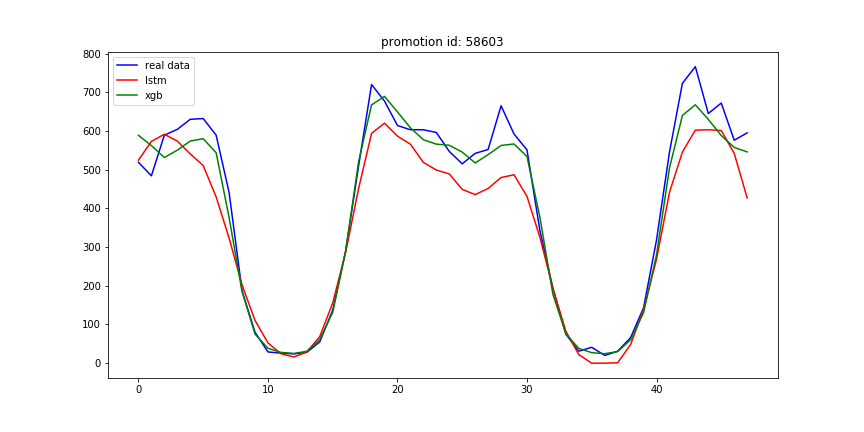
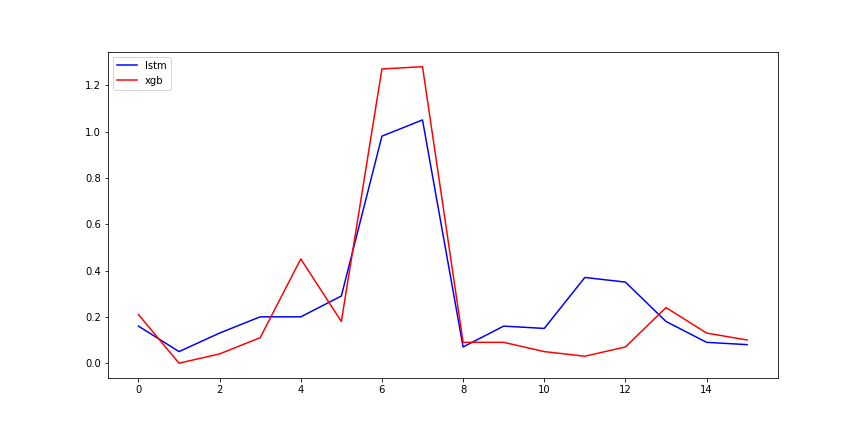
未来48小时结果对比:
模型性能
绝对差值比计算公式:
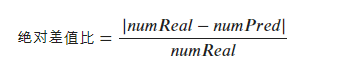
- 未来48小时绝对差值比
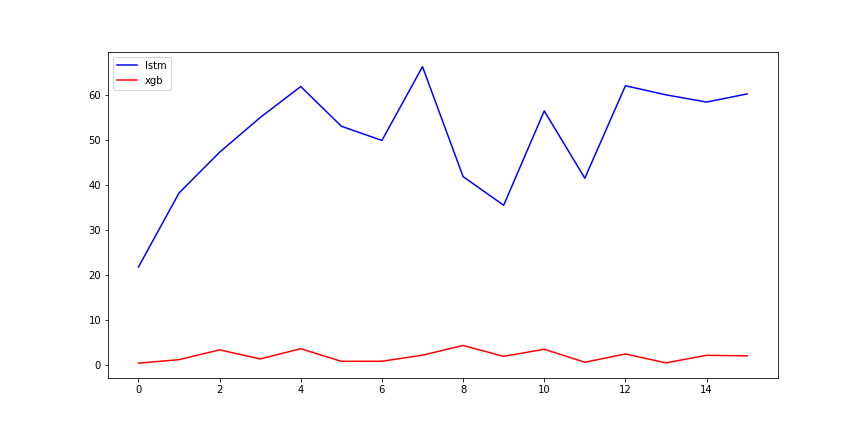
- Mean Absolute Errors
- Train and inferance time (s)
总结
两种模型在变化相对规律的时间序列上效果都不错,但在变化不规律的序列上效果欠佳。XGBoost通过仔细调节超参,能够达到与LSTM相差不大的结果。LSTM耗时上显然比不过XGBoost,但LSTM相比XGBoost更不容易出现过拟合。